
Salam Java…
Kali ini saya akan sedikit sharing mengenai salah satu fungsi library Stanford Parser di Java. Library macam apa itu? yang jelas bukan semacam tahu telor [kok jadi ngomongin makanan] 😀 .Oke begini, di dalam dunia NLP (Natural Language Processing) stanford parser dapat digunakan untuk membantu kita dalam melakukan teknik parsing. Bahasa yang available support untuk stanford parser ini adalah English, Chinese dan Arabic. Bagaimana dengan parsing Bahasa Indonesia? [out of topic ye…]. Oke kalau mau kenalan lebih lanjut dengan stanford silakan kunjungi link ini. Silakan unduh library-nya, dan mari kita oprek sama-sama. Terserah mau pakek IDE apa, kali ini saya menggunakan Netbeans 7.2 untuk membantu mengerjakan stanford parser ini. Oh ya jangan lupa untuk mengunduh englishPCFG.ser.gz
Ini contoh code dalam stanford
[code language=”java”]
package cobastanford.program;
import edu.stanford.nlp.objectbank.TokenizerFactory;
import edu.stanford.nlp.parser.lexparser.LexicalizedParser;
import edu.stanford.nlp.process.PTBTokenizer;
import edu.stanford.nlp.process.WordTokenFactory;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.trees.TreePrint;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.StringReader;
import java.util.List;
/**
*
* @author yuitaarumsari
*/
public class Parsing {
public static void main(String[] args) throws FileNotFoundException, IOException {
String text = "System should be able to handle many queries."
+ "Interaction between user and system should be easy.";
LexicalizedParser lp = new LexicalizedParser("englishPCFG.ser.gz");;
TreePrint tp = new TreePrint("penn");
TokenizerFactory tf = PTBTokenizer.factory(false, new WordTokenFactory());
List tokens = tf.getTokenizer(new StringReader(text)).tokenize();
lp.parse(tokens); //parsing menjadi token-token
Tree t = lp.getBestParse(); // get the best parse tree
System.out.println("\nPROCESSED:\n\n");
tp.printTree(t); // print tree
}
}
[/code]
Begitulah adanya program sederhana di dalam stanford. Output dari program diatas dapat dilihat pada gambar dibawah :
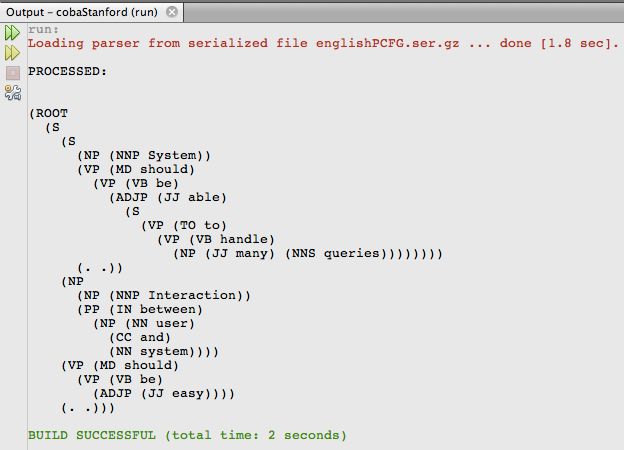
Pada baris 24 dalam code terdapat baris perintah
[code language=”java”]
TreePrint tp = new TreePrint("penn");
[/code]
Baris tersebut digunakan untuk mengeluarkan jenis output parsing tree yang kita ingikan, misalnya pada contoh ingin mengeluarkan output dengan bentuk tree, selain bentuk tersebut, jenis parameter yang dapat digunakan diantaranya :
“penn”, // constituency parse
“oneline”,
rootLabelOnlyFormat,
“words”,
“wordsAndTags”, // unstemmed words and pos tags
“dependencies”, // unlabeled dependency parse
“typedDependencies”, // dependency parse
“typedDependenciesCollapsed”,
“latexTree”,
“collocations”,
“semanticGraph”
Pada skrinsut sistem terdapat tag PP,NP,S, apa itu maksudnya? Nah daripada panjang kan ya lebih baik langsung cekidot 😀
|
Number
|
Tag
|
Description
|
| 1. | CC | Coordinating conjunction |
| 2. | CD | Cardinal number |
| 3. | DT | Determiner |
| 4. | EX | Existential there |
| 5. | FW | Foreign word |
| 6. | IN | Preposition or subordinating conjunction |
| 7. | JJ | Adjective |
| 8. | JJR | Adjective, comparative |
| 9. | JJS | Adjective, superlative |
| 10. | LS | List item marker |
| 11. | MD | Modal |
| 12. | NN | Noun, singular or mass |
| 13. | NNS | Noun, plural |
| 14. | NNP | Proper noun, singular |
| 15. | NNPS | Proper noun, plural |
| 16. | PDT | Predeterminer |
| 17. | POS | Possessive ending |
| 18. | PRP | Personal pronoun |
| 19. | PRP$ | Possessive pronoun |
| 20. | RB | Adverb |
| 21. | RBR | Adverb, comparative |
| 22. | RBS | Adverb, superlative |
| 23. | RP | Particle |
| 24. | SYM | Symbol |
| 25. | TO | to |
| 26. | UH | Interjection |
| 27. | VB | Verb, base form |
| 28. | VBD | Verb, past tense |
| 29. | VBG | Verb, gerund or present participle |
| 30. | VBN | Verb, past participle |
| 31. | VBP | Verb, non-3rd person singular present |
| 32. | VBZ | Verb, 3rd person singular present |
| 33. | WDT | Wh-determiner |
| 34. | WP | Wh-pronoun |
| 35. | WP$ | Possessive wh-pronoun |
| 36. | WRB | Wh-adverb |
Oke teman-teman sekian dulu ye…sementara hanya ini yang bisa diuprek, semoga bisa membantu… 🙂 Tetep semangat! ^_^
References
- Kuliah Rekayasa Perangkat Lunak
- http://pastebin.com/Nipr2WzE
- http://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
maaf,ini kn yg untuk bahasa inggris,,ada ga yg buat tree parsing tapi datanya dalam bahasa indonesia?makasih 🙂
@rina sepengetahuan saya masih terbatas referensinya
maaf mau tanya, saya sedang mencoba program yg kaka buat, tp kalo saya kok ketika penulisan code Tree t = lp.getBestParse(); nya error ya? kesalahan ada di method getBestParse() nya .. mohon bantuannya terimakasih
@dira: Hai mba/mas Dira. Kira2 bunyi errornya yang di method getBestParse() itu apa ya? 🙂
assalamualaikum,
saya mau bertanya kalau hasilnya di jadikan .txt bagaimana? mohom pencerahannya
Waalaikumsalam we wb.
Mohon maaf mas, saya sudah lama sekali tidak uprek-uprek ini. 🙂